Low-latency data processing ensures businesses can act on information almost instantly, transforming live data into actionable insights. This article details six tools that excel in this area, each tailored for specific needs:
- Apache Kafka: Handles massive event streams with sub-millisecond latency, ideal for high-throughput messaging and event-driven systems.
- Apache Flink: Perfect for stateful stream processing with exactly-once guarantees, handling out-of-order events efficiently.
- Apache Spark: Combines real-time and batch processing using an in-memory model, suitable for analytics and machine learning tasks.
- Fivetran: Automates ELT pipelines with 5–15 minute latencies, simplifying data integration for marketing and business analytics.
- Informatica: Offers sub-second latency with Change Data Capture (CDC) for enterprises needing governance and compliance.
- Hevo Data: A no-code platform providing near real-time data synchronization, accessible for non-technical teams.
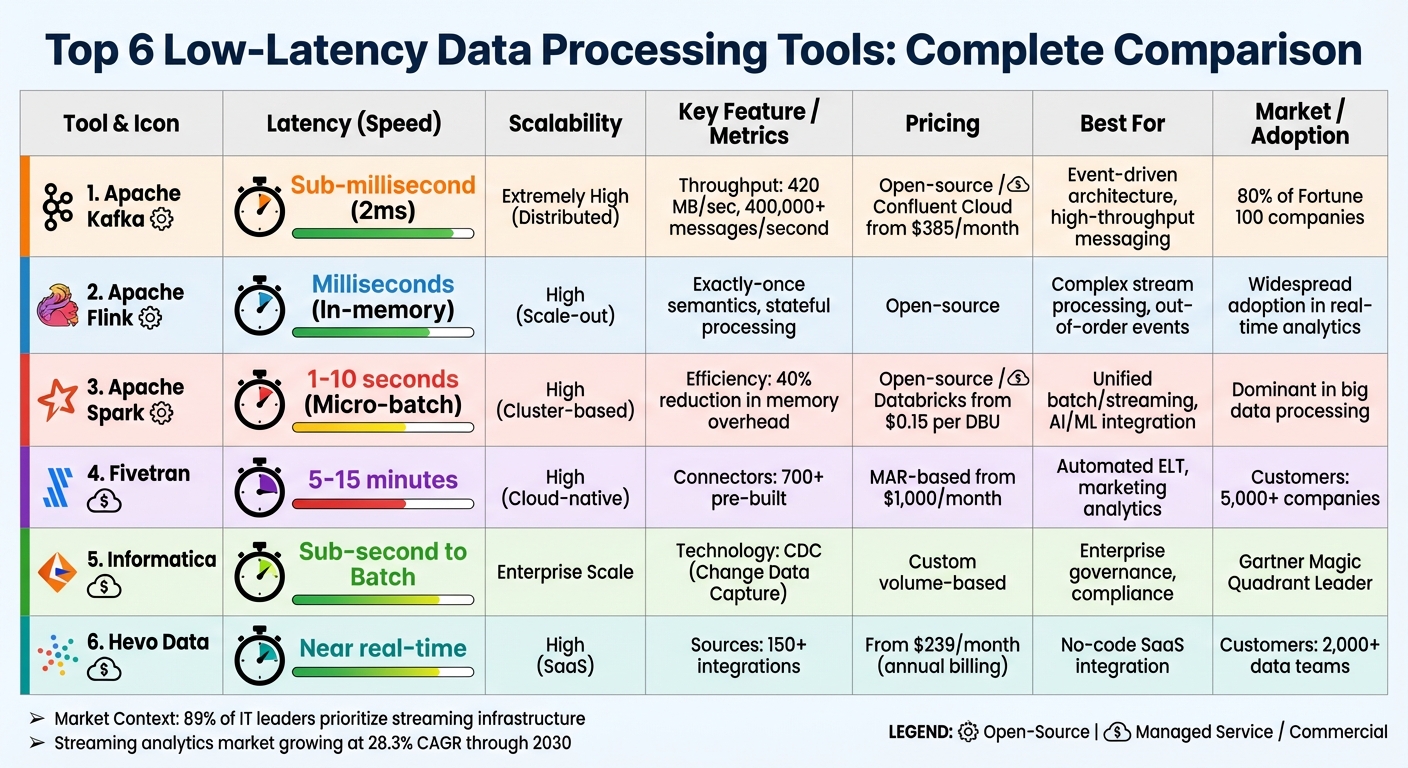
Quick Comparison
| Tool | Latency | Best For | Pricing Model |
|---|---|---|---|
| Apache Kafka | Sub-millisecond | Event-driven systems, high throughput | Open-source / Confluent Cloud ($385+) |
| Apache Flink | Milliseconds | Stateful processing, exactly-once tasks | Open-source |
| Apache Spark | 1–10 seconds | Unified analytics, AI/ML pipelines | Open-source / Databricks ($0.15/DBU) |
| Fivetran | 5–15 minutes | Automated ELT, marketing analytics | MAR-based ($1,000+/month) |
| Informatica | Sub-second | Enterprise workflows, compliance | Custom volume-based |
| Hevo Data | Near real-time | No-code SaaS integration | Subscription ($239+/month) |
These tools help businesses reduce delays in data processing, enabling faster decisions in areas like fraud detection, personalized marketing, and dynamic pricing. Selecting the right tool depends on your latency needs, technical expertise, and scalability requirements.
Low-Latency Data Processing Tools Comparison: Features, Pricing, and Performance
Race to Real-Time: Low-Latency Streaming ETL With Next-Gen OLTP-DB
Top Tools for Low-Latency Data Processing
Choosing the right platform can mean the difference between acting on data in real-time or lagging behind. Below are six tools tailored for low-latency data processing, each offering distinct features to suit various needs.
Apache Kafka

Apache Kafka is a distributed event streaming platform built to handle massive data volumes with minimal delays. It delivers message latencies as low as 2 milliseconds. Thanks to its partitioned, replicated architecture, Kafka ensures fault tolerance and high availability.
This platform powers 80% of Fortune 100 companies, managing trillions of messages daily. From real-time fraud detection in finance to tracking live user activity in e-commerce, Kafka excels at building real-time data pipelines that connect multiple systems seamlessly.
Apache Flink

Apache Flink focuses on stateful stream processing, making it ideal for both unbounded and bounded data streams. Its standout feature is event-time processing with exactly-once state consistency. This means Flink processes events based on their actual occurrence rather than their arrival time.
Flink shines in handling out-of-order or late-arriving events. Its robust fault tolerance and precision make it well-suited for complex real-time analytics that demand high accuracy.
Apache Spark
Apache Spark uses an in-memory processing model to support both real-time streaming and batch processing. By keeping data in memory instead of writing it to disk, Spark significantly reduces processing time for large-scale analytics.
Spark’s flexibility makes it a favorite among enterprise analytics teams. It powers applications like real-time recommendation engines and machine learning pipelines while maintaining the speed required for low-latency tasks.
Fivetran
Fivetran automates the ELT (Extract, Load, Transform) process with fully managed pipelines. With over 700 pre-built connectors, it adapts automatically to schema changes, eliminating manual adjustments.
For marketing teams juggling data from multiple SaaS platforms, Fivetran simplifies integration. It achieves latencies of 5–15 minutes, ideal for marketing analytics. Serving over 5,000 companies worldwide, Fivetran uses a Monthly Active Rows (MAR) pricing model that scales with usage.
Informatica
Informatica’s cloud-based platform supports enterprise-grade data workflows with sub-second latency, driven by Change Data Capture (CDC) technology. Its AI-powered intelligent mapping suggests transformations while maintaining strict governance across workflows.
A Leader in the Gartner Magic Quadrant for Data Integration Tools, Informatica is perfect for enterprises requiring data lineage tracking and compliance. Its CDC technology streams database changes continuously, avoiding the overhead of full table scans. Pricing is customized based on volume.
Hevo Data
Hevo Data offers a no-code platform for real-time data synchronization from over 150 sources. Its automatic schema management and built-in fault tolerance make it user-friendly for non-technical teams.
Hevo serves over 2,000 data teams, earning praise for its simplicity. It provides a free tier and paid plans starting at $239 per month (billed annually). For teams without dedicated data engineers, Hevo simplifies real-time pipelines, making them accessible to everyone.
The following feature comparison highlights the unique strengths of these platforms.
Feature Comparison
Choosing the right platform hinges on understanding how each balances latency, scalability, and cost. The table below highlights the key differences among six popular tools. While open-source platforms demand engineering expertise and infrastructure management, managed services provide automated, hands-off solutions.
| Tool | Latency | Scalability | Pricing Model | Best For |
|---|---|---|---|---|
| Apache Kafka | Sub-millisecond | Extremely High (Distributed) | Open-source / Usage (Confluent Cloud starts at $385/month) | Event-driven architecture, high-throughput messaging |
| Apache Flink | Milliseconds (In-memory) | High (Scale-out) | Open-source | Complex stream processing, exactly-once semantics |
| Apache Spark | 1–10 seconds (Micro-batch) | High (Cluster-based) | Open-source / Consumption (Databricks starts at $0.15 per DBU) | Unified batch/streaming, AI/ML integration |
| Fivetran | 5–15 minutes | High (Cloud-native) | MAR-based (starts around $1,000/month for enterprise) | Automated ELT, zero-maintenance pipelines |
| Informatica | Sub-second to Batch | Enterprise Scale | Custom Volume-based | Enterprise governance, regulatory compliance |
| Hevo Data | Near Real-time | High (SaaS) | Subscription (starting at $239/month) | Mid-market SaaS integration, no-code requirements |
Let’s delve deeper into performance metrics and real-world use cases to better grasp these tools' strengths.
Apache Kafka stands out for its raw throughput, capable of sustaining 420 MB/sec and processing over 400,000 messages per second on standard hardware. Major players like LinkedIn and Netflix rely on Kafka to manage trillions of messages daily, powering their recommendation engines and other large-scale systems.
On the other hand, Apache Flink shines with its ability to handle stateful computations and ensure exactly-once semantics. Meanwhile, Apache Spark uses a micro-batch processing model, typically delivering 1–10 second latencies. While these open-source tools offer flexibility, managed services like Confluent Cloud and Databricks follow consumption-based pricing models. This can result in unpredictable costs, especially as usage scales.
For businesses prioritizing simplicity over ultra-low latency, tools like Fivetran and Hevo Data offer automated pipelines with predictable subscription pricing. These platforms are particularly appealing for organizations that want reliable data integration without the need for extensive engineering resources.
Understanding these distinctions is key to optimizing your data processing system and reducing latency where it matters most.
sbb-itb-5174ba0
How to Reduce Latency in Data Processing
Lowering latency in data processing requires a mix of smart system design and technical fine-tuning to eliminate bottlenecks. The standard for latency has evolved significantly - what used to be acceptable as 15-minute batch windows has now been replaced by sub-60-second expectations for tasks like operational analytics and fraud detection [5, 19]. As Donal Tobin from Integrate.io puts it:
"True real-time ETL now means sub‑60 second latency for operational analytics and fraud detection, replacing outdated 15‑minute batch windows."
This shift has paved the way for advanced methods to process data faster and more efficiently.
One standout method is Change Data Capture (CDC). By using log-based CDC, transaction logs are monitored to capture inserts, updates, and deletions as they happen. This method avoids overloading source systems with queries and allows for continuous data movement, ensuring insights are available mere seconds after events occur [5, 19]. It’s a powerful way to handle real-time data without straining production databases.
Another key technique is in-memory processing, which significantly cuts delays by keeping frequently accessed data in RAM. Tools like Redis, Memcached, or Apache Ignite act as distributed in-memory data stores, delivering "hot data" almost instantly [26, 27]. When paired with streaming architectures that process events as they arrive - rather than grouping them into micro-batches - this approach delivers insights in milliseconds.
Other optimizations include using compact serialization formats like Apache Avro or Protocol Buffers to reduce network bandwidth usage. Edge preprocessing can filter data at its source before transmission, and asynchronous processing boosts concurrency by handling multiple tasks simultaneously [26, 27]. These techniques are particularly effective in scenarios like marketing analytics, where real-time personalization (e.g., updating e-commerce recommendations based on a user’s browsing behavior) or instant fraud detection in financial transactions is essential [2, 5].
Lastly, partitioning data streams by keys, such as User ID, allows for parallel processing, cutting down on queuing delays. Meanwhile, watermark strategies help balance waiting for late-arriving data with the need for timely results. These methods, when implemented together, transform high-volume data streams from tools for retrospective analysis into systems that enable proactive, real-time decision-making.
Conclusion
Choosing the right low-latency tool can dramatically improve your business's ability to respond quickly. With 89% of IT leaders identifying streaming infrastructure as a top business priority, the move from overnight batch processing to sub-60-second analytics has become the standard for enterprises. The tools discussed here - from the high-performance capabilities of Apache Kafka to the automated CDC pipelines offered by Fivetran - are designed to tackle the latency challenges that marketing and business teams encounter every day.
Speed in data processing is more than just a technical achievement; it’s a business necessity. Whether it’s delivering personalized product recommendations to customers while they’re still browsing or detecting fraud as it happens, every millisecond counts. Advanced BI analytics can accelerate decision-making by up to five times, giving businesses a critical advantage in competitive markets.
The key is aligning your latency needs with the right architecture. Tools like Kafka and Flink are ideal for ultra-fast, millisecond-level tasks like fraud detection. On the other hand, solutions such as Spark Streaming, which uses micro-batching, can cut in-memory overhead by around 40%, making it a strong choice for operational reporting. Meanwhile, platforms like Hevo Data and Informatica simplify maintenance with automated workflows, and AI advancements are expected to reduce manual data management tasks by nearly 60% by 2027. These systems enable real-time decision-making that can set your business apart.
Start by defining your latency requirements - whether it’s sub-millisecond for trading or sub-minute for personalized marketing - and look for tools with pre-built connectors to streamline implementation. With the streaming analytics market projected to grow at a 28.3% CAGR through 2030, investing in low-latency infrastructure today ensures you can turn real-time data into immediate, impactful actions.
If you’re ready to explore more options, the Marketing Analytics Tools Directory is a great resource. It offers a curated list of real-time analytics tools, business intelligence solutions, and enterprise platforms to help you find the perfect fit for your low-latency data processing needs.
FAQs
What should I look for in a low-latency data processing tool?
When picking a tool for low-latency data processing, there are a few critical factors to weigh. First, speed is a top priority - especially if you're dealing with real-time dashboards or operational data. The tool should provide insights almost instantly to keep up with fast-moving data.
Next, think about scalability. Your tool needs to handle increasing data volumes and shifting workloads without losing performance. This is crucial as your needs grow over time.
Don't overlook integration and usability. The tool should work seamlessly with your current systems, support widely-used standards like SQL or APIs, and be straightforward to set up and manage. Lastly, take a hard look at cost and security features to ensure they fit within your budget and meet compliance needs. By keeping these factors in mind, you'll be better equipped to find a solution that’s both reliable and efficient.
What role does Change Data Capture (CDC) play in minimizing data processing delays?
Change Data Capture (CDC) reduces delays in data processing by continuously monitoring and streaming updates directly from transaction logs. This approach removes the need for lengthy batch processing or full data extractions, ensuring a quicker and smoother flow of information.
With instant access to incremental updates, CDC technology powers low-latency data pipelines, making it a crucial resource for businesses that depend on real-time analytics and quick decision-making.
What’s the difference between Apache Kafka and Apache Flink for real-time data processing?
Apache Kafka and Apache Flink play distinct but complementary roles in handling real-time data. Apache Kafka acts as a distributed messaging system, built for high-throughput and fault-tolerant event storage and streaming. It’s perfect for creating scalable pipelines and reliably moving data between systems. With its log-based architecture, Kafka ensures data durability, making it a reliable choice as the backbone for event streaming.
Meanwhile, Apache Flink is a stream processing framework tailored for complex, stateful data transformations in real time. It shines in scenarios like windowing, aggregations, and maintaining exactly-once processing semantics. Flink’s dataflow architecture is designed for advanced analytics and fault-tolerant stream processing. While Kafka focuses on storing and transporting raw event streams, Flink takes those streams and processes them to extract meaningful insights. Together, they form a powerful duo for real-time data workflows.


