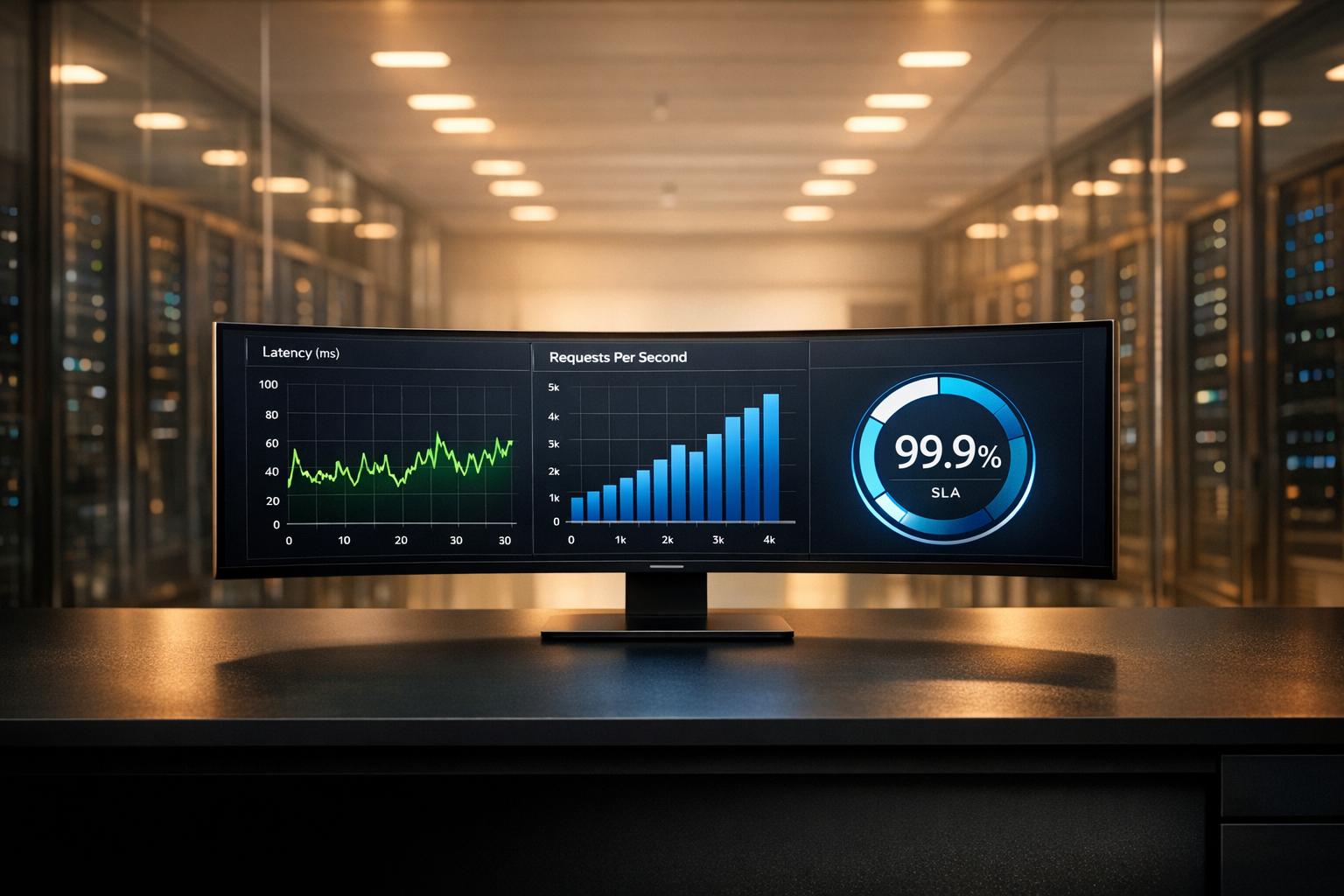
If your marketing data is 12 to 36 hours late, you're making budget and campaign calls too late. I’d use Apache Flink when I need real-time marketing metrics, per-user event tracking, and exact counts for spend, clicks, and conversions.
Here’s the short version:
- Flink processes event streams as they arrive, not in big daily batches.
- Event time + watermarks help me count late clicks, impressions, and conversions the right way.
- Stateful processing lets me track sessions, funnels, and user paths without hitting a database on every event.
- Stream joins connect impression, click, conversion, and profile data for live attribution and triggers.
- Exactly-once delivery matters when the numbers tie to ad spend, revenue, and billing.
- Dual outputs are common: one path to live dashboards, another to Snowflake, BigQuery, or other warehouses.
A few numbers make the case fast:
- Oracle reported about 1.2-second end-to-end trigger latency.
- Expedia stopped a bad test after a -39% conversion impact showed up in live monitoring.
- A 2026 attribution setup handled 18 billion daily impressions with 87 ms P99 latency for dashboard updates.
If I had to boil it down to one idea, it’s this: Flink fits when I need to act on marketing events now, not tomorrow morning.
Compared with micro-batch tools, Flink is a better match for:
- live campaign pacing
- A/B test guardrails
- session-based attribution
- funnel drop-off checks
- personalization triggers
- fraud and invalid-traffic checks
I’d keep the stack simple if the team only needs after-the-fact reporting. But if late events, cross-channel joins, and sub-minute updates matter, Flink is often the better pick.
| Area | What matters |
|---|---|
| Best fit | Live attribution, personalization, experiment monitoring |
| Core methods | Event time, watermarks, windows, keyed state, joins |
| Accuracy | Exactly-once checkpoints for money-related metrics |
| Outputs | Live dashboards + cloud warehouse reporting |
| Main tradeoff | More setup work in exchange for live decision support |
That’s the core of the article: how I’d use Flink to turn raw marketing events into live, trusted signals for dashboards, triggers, and attribution.
Apache Flink: The Fabric of Real-Time Data Processing & Streaming Analytics | Uplatz
sbb-itb-5174ba0
Building Marketing Event Streams in Apache Flink
Marketing events rarely show up in perfect order. One click lands on time, an impression arrives late, and a conversion can drift in after both. That’s why Kafka works well as the ingest buffer. Partition by userId to keep each user’s event sequence in order, and use Avro with Schema Registry so schema changes don’t turn into a mess. Once that stream is in shape, Flink can turn raw event data into marketing KPIs you can trust.
Use Event Time, Watermarks, and Windows for Accurate KPIs
Once events are in Flink, the job is to make timing reliable enough for KPI math.
Use event time for stable marketing KPIs. Set watermarks with 10–20 seconds of bounded lateness so delayed clicks and impressions still count. Watermarks show how far event time has moved forward. Use allowedLateness to accept late conversions after the watermark has passed, and send very late events to a side output for audit or reconciliation.
Pick the window based on the metric you’re measuring:
| Window Type | Marketing Use Case | Behavior |
|---|---|---|
| Tumbling | Per-minute campaign metrics like clicks and impressions | Fixed-size, non-overlapping intervals |
| Sliding | Rolling engagement patterns over time | Overlapping intervals that capture trends |
| Session | User journey analysis | Dynamic size based on inactivity gaps |
Use WatermarkStrategy.withIdleness() so one idle Kafka partition doesn’t hold back watermark progress for the whole job.
Detect Campaign Patterns with Stateful Processing and CEP
Once timestamps are lined up, Flink can follow each user’s path across multiple steps.
When you key the stream by userId, Flink sends events from the same user to the same operator instance. That lets it keep per-user state, such as the last viewed category or recent action frequency. From there, Flink CEP can detect ordered sequences like impression → click → add-to-cart → conversion. For example, a sliding 10-minute window keyed by userId can spot a user who clicked three different products but never added anything to the cart, then trigger a personalized nudge.
For invalid-traffic monitoring, a three-tier filter helps catch ad fraud in-stream:
- Stateless IP/User-Agent blocklists
- Stateful click-frequency windows
- Asynchronous ML scoring
Vendor estimates put raw invalid traffic on search campaigns at 14% to 22%.
"We chose Flink because it solves a very real problem: delivering stateful, low-latency, and intelligent data processing at scale." - Pooja Ravi, Software Engineer, Oracle
For large-scale state, like a 30-day attribution window, use the RocksDB state backend with incremental checkpointing to cloud object storage such as S3. Set a time-to-live (TTL) on idle state, such as 24 hours, so inactive user records expire on their own instead of piling up over time.
Stream Joins and Latency Control for Live Campaign Monitoring

Apache Flink vs. Spark Streaming for Marketing Analytics
Join Impressions, Clicks, Conversions, and Profile Data
Once event-time windows and CEP are in place, the next job is to combine live user behavior with campaign and profile data. That sounds simple on paper. In practice, the whole thing falls apart if joins add too much lag.
A clean way to do this in Flink is to key each stream on user_id, which lets Flink match events through shared per-user state. For lower-frequency metadata, like campaign rules or audience definitions, use Broadcast State. That lets teams update targeting logic while the job is still running instead of stopping everything for a restart.
At the same time, high-volume click and impression events can keep flowing as-is. And when you need outside context, like ML scoring or CRM enrichment, AsyncDataStream helps you call external systems without blocking the pipeline. If you're tracking behavior sequences, Flink SQL MATCH_RECOGNIZE can spot Impression → Click → Purchase patterns inside a time window without custom code.
Oracle Marketing Cloud used this setup to join email click events with campaign metadata through broadcast state, pull user context from keyed state, and trigger personalized push notifications through Oracle Responsys at about 1.2 seconds of end-to-end latency.
"Flink's event time model ensures correctness regardless of late arrivals or clock skews." - Pooja Ravi, Software Engineer, Oracle
Manage Latency, Backpressure, and Exactly-Once Accuracy
These joins only matter if they stay fast enough for live decisions. If the pipeline slows down under load, campaign monitoring stops feeling “live” pretty fast.
Flink handles backpressure natively. When a downstream sink slows, upstream operators throttle automatically to match it, which helps prevent data loss during traffic spikes. That kind of load is not theoretical either. During the 2020 Double 11 festival, Alibaba's Flink-based system processed a peak of 4 billion records per second and 7 TB of data per second.
Exactly-once accuracy matters most when money is involved: ad spend, impression counts, and conversion revenue. Flink uses distributed checkpoints and two-phase commit so billing metrics stay exact across Kafka and upsert-capable databases. Data is only committed to the sink after a successful checkpoint, so the checkpoint interval sets the delay window directly.
Uber's Ads team used a 2-minute checkpoint interval for its UberEats ad system. That gave them a middle ground: low enough overhead, but still near-real-time budget visibility for advertisers. They also paired it with unique record UUIDs so downstream systems could deduplicate replayed events. One more detail that saves headaches: match consumer parallelism to Kafka partition count so you don't end up with idle tasks.
Apache Flink vs. Other Stream Processors: A Marketing Workload Comparison
Once the join setup and sink behavior are nailed down, picking a processor gets a lot easier. For marketing workloads, the tradeoff between Flink and Spark Streaming usually comes down to speed, state handling, and how much work you're willing to do by hand.
| Feature | Apache Flink | Spark Streaming (Micro-batch) |
|---|---|---|
| Latency | Sub-second (continuous processing) | Seconds (micro-batch intervals) |
| State Management | Native, fine-grained keyed state | Checkpointing of RDDs/DataFrames |
| Pattern Matching | Native MATCH_RECOGNIZE via CEP |
Complex manual implementation |
| Exactly-Once Accuracy | Native via checkpointing and two-phase commit | Exactly-once with limitations |
| Best Use | Real-time triggers, live funnels, attribution | Post-campaign reporting and attribution |
For live budget pacing, personalization, and experiment monitoring, Flink's continuous model is the better fit.
Sending Flink Output to Dashboards and Cloud Warehouses
After Flink joins and enriches marketing events, the next step is getting that data where people can use it. Usually, that means one of two places: a live serving layer for fast dashboard updates, or a warehouse for reporting and attribution work.
Once event-time logic and joins are set up, the sink you pick shapes how fast trusted metrics show up for users.
Feed Real-Time Dashboards and Low-Latency Stores
For live monitoring, Flink can send aggregates to Redis or ClickHouse, or publish to Kafka-backed WebSocket feeds that keep dashboards up to date. Redis works well for sub-100 ms lookups. ClickHouse is a better fit for high-concurrency trend analysis, Top-N views, and anomaly queries.
Here’s what that looks like at scale. In February 2026, a streaming attribution system was designed to handle 18 billion daily impressions - about 208,000 events per second. It used Flink for 30-minute sessionization and pushed updates every 5 seconds through WebSockets to a React dashboard. The system reached a P99 latency of 87 ms.
So the sink choice comes down to a simple tradeoff: live speed versus deeper downstream analysis.
Load Cloud Warehouses for Reporting and Attribution Analysis
The other path sends data into cloud warehouses like Snowflake, BigQuery, or Oracle Autonomous Database. In this setup, Flink works like a continuous ETL layer. It enriches raw events with campaign metadata, parses UTM parameters, adds user profile data, and writes clean records that teams can query with SQL.
In May 2025, Oracle engineers wrote enriched click and email interaction data into Oracle Autonomous Database for long-term ML feedback and A/B analysis.
For reporting, warehouse sinks hold clean records so downstream teams can trust revenue, spend, and conversion numbers using analytics tools for business. Checkpoint intervals - usually between 30 and 60 seconds - decide how often Flink commits data to these sinks.
Choosing the Right Sink: Latency, Cost, and Query Needs
The right sink depends on who needs the data and how fast they need it.
| Feature | Real-Time Dashboards / Low-Latency Stores | Cloud Data Warehouses |
|---|---|---|
| Latency | Sub-second to a few seconds | Minutes to hours (depending on checkpointing) |
| Typical Tech | Redis, ClickHouse, PostgreSQL, Hologres | Snowflake, BigQuery, Oracle Autonomous DB |
| Query Complexity | Point queries, aggregations, Top-N | Complex SQL, multi-touch attribution, finance |
| Cost Control | Higher, due to always-on compute and memory needs | Lower, with storage-optimized tiers for long-term reporting |
| Stakeholder Fit | Ad Ops, Live Campaign Managers | Marketing Analysts, Finance, Executives |
Many teams run both paths from the same Flink job. One branch supports live campaign operations. The other feeds long-term analysis and reporting.
Conclusion: When Apache Flink Is the Right Choice for Cloud Marketing Analytics
Once you’ve picked between dashboard and warehouse sinks, the next call is simpler: is Flink worth the operational overhead compared to other real-time marketing analytics tools?
Use Apache Flink when your marketing team needs to act on live event data, not hours later. It makes sense when decisions rely on stateful processing and clean downstream metrics. In plain English, Flink works best when batch pipelines are too slow and you need one pipeline to support both real-time action and reporting.
Flink earns its keep when you need things like sessionization, funnel detection, interval joins, and exactly-once delivery. If you don’t need that level of processing, a simpler setup may do the job with less effort.
Key Takeaways for Marketers and Decision-Makers
For most teams, the choice comes down to a handful of practical checks:
| Decision Area | What to Know |
|---|---|
| When Flink fits | Live attribution, A/B test monitoring, and personalization triggers require it |
| Data patterns | Out-of-order events, sessionization, multi-step funnels, stream joins |
| Campaign monitoring | Expedia's Circuit Breaker caught a -39% conversion impact within minutes |
| Output architecture | Dual-sink: one branch for live dashboards, one for reporting and attribution |
FAQs
When is Flink worth the extra setup?
Apache Flink makes sense when your marketing setup needs low-latency decisions that happen as events come in, not hours later in a batch job.
That matters when you're dealing with high-throughput streaming data and use cases like immediate sessionization, real-time funnel analysis, or streaming AI inference. In those cases, waiting for batch processing just doesn't cut it.
Flink also helps you stay accurate under pressure. It supports exactly-once processing, fault tolerance, and out-of-order events, which is a big deal when data arrives late, arrives twice, or shows up in the wrong sequence.
How does Flink handle late marketing events?
Apache Flink deals with late marketing events by using event time. That matters because it keeps results correct even when clocks don’t line up or events show up late.
For windowed operations, allowedLateness gives Flink extra time before it drops late data. So if an event arrives after the first window result was produced, Flink can still update that earlier result.
If you need tighter real-time control, source-level settings can route late events to a dedicated system table instead. That gives you a clean place to inspect them later or backfill missing data without mixing them into the main stream right away.
What should go to dashboards versus warehouses?
Dashboards are built for low-latency, real-time monitoring of active marketing campaigns. They should rely on aggregated or cached data so teams can get near-immediate feedback on metrics like click-through rates, attribution scores, and overall campaign health.
Warehouses are a better fit for historical analysis, more complex aggregations, and long-term storage. Apache Flink can stream data to both. But when you need a place for persistent, high-volume data and deeper queries, warehouses are the right destination.