Most old attribution setups now miss a big share of what users do. In 2026, I’d treat privacy-centric attribution as a mix of first-party data, modeled conversions, aggregate reporting, and testing instead of one “perfect” tracking system.
Here’s the short version:
- Third-party cookies, ATT, and state privacy laws changed measurement.
- Legacy browser-side tracking now sees only about 25% to 40% of actual visitor behavior.
- Identity coverage for old multi-touch setups has dropped to roughly 30%–60%.
- 78% of marketers say privacy-first attribution is a top priority, but only 32% feel ready.
- MMM is better for budget planning.
- MTA and platform conversion reporting are better for day-to-day channel tuning.
- Incrementality tests are how I’d check whether a channel caused sales.
- Server-side setup and consented first-party data should come before expensive tools.
If I were setting this up today, I’d keep it simple: use server-side collection, split reporting into observed and modeled conversions, compare platform numbers against back-end sales, and use the model that fits the decision. That means daily optimization with near-term attribution, quarterly planning with MMM, and channel checks with holdout or geo-lift tests.
A quick way to think about it: privacy-centric attribution is less about exact user paths and more about making sound budget decisions with partial data.
Privacy-Centric Attribution In Modern Marketing Measurement
What Privacy-Centric Attribution Means In 2026
In plain terms, privacy-centric attribution estimates channel contribution from aggregated, modeled signals instead of user-level paths. It pulls from server-side logs, hashed first-party IDs, contextual signals, and statistical inference to estimate how much each channel contributed. That shift changes how teams read conversion paths, channel contribution, and ROI.
The old playbook assumed you could follow people across touchpoints with a high degree of certainty. That’s no longer the case. Identity coverage for old-school multi-touch attribution has dropped from over 90% in the cookie era to about 30%–60% by 2026. When coverage falls that much, channel analysis starts from partial data, conversion paths become incomplete, and the output works more like a directional guide than an exact count.
Why U.S. Marketers Need New Measurement Assumptions
Several privacy changes are hitting at the same time, and together they’ve changed the math.
Safari's ITP can cap server-set cookie lifetimes at 7 days - and as little as 24 hours on some redirect-based journeys. Chrome has deprecated third-party cookies. Apple's App Tracking Transparency led 75–85% of iOS users to decline tracking prompts. CCPA/CPRA and other state privacy laws require consent, data minimization, and deletion rights. Put all that together, and the pool of trackable audiences gets smaller. Attribution also starts to lean toward users who still leave durable identifiers.
| Change driver | Effect on attribution practice | Practical implication |
|---|---|---|
| Privacy laws (CCPA/CPRA/state laws) | Require consent, data minimization, deletion rights | Fewer trackable journeys; consent-aware measurement needed |
| Browser restrictions (Safari/Firefox/Chrome) | Block or limit third-party cookies and cross-site tracking | More missing identifiers; reliance on first-party/server-side data |
| Mobile OS rules (iOS ATT) | Reduce device-level tracking and ad ID access | Lower match rates; greater use of modeled conversions |
| Consumer consent expectations | More users decline tracking | Attribution undercounts privacy-conscious audiences |
That’s why modern attribution no longer leans on one user-level model. It now uses a mix of methods because one lens alone won’t give you the full picture.
How Privacy-Centric Attribution Differs From Legacy Multi-Touch Attribution
Legacy multi-touch attribution stitched together individual user paths with third-party cookies and mobile device IDs. In theory, that gave marketers granular, deterministic views. In practice, much of that detail has faded.
Legacy MTA = user-level stitching; privacy-centric attribution = aggregate reliability.
Modern measurement now works more like a three-part stack. Marketing Mix Modeling (MMM) supports budget allocation across all channels, including offline, without needing identity data. Privacy-centric attribution supports near-term optimization at the session or cohort level. Incrementality testing serves as the validation layer, using geo-holdouts or controlled experiments to check whether a channel actually caused a conversion.
The market is already moving this way. In 2026, 27.6% of U.S. marketers rate MMM as their most reliable measurement method, compared to 19.4% for multi-touch attribution. Cohort analysis also plays a part by tracking long-term value by acquisition source without needing individual-level tracking. Each method answers a different question. The next section breaks down the model types in this stack and when to use each.
sbb-itb-5174ba0
[Webinar] Data privacy trends to watch in 2026
Core Privacy-Safe Attribution Model Types
Privacy-Centric Attribution Models Compared: Which to Use & When (2026)
Once privacy limits are in place, the next step is simple: pick the model that fits the decision and the signal you still have.
That’s where things get tricky. These model families aren’t separated just by name. They differ by how much signal they can still observe. And that gets to the heart of privacy-first measurement: granularity, speed, and confidence almost never show up together in one model.
Rule-Based And Data-Driven Models With Partial Signals
Rule-based models - like last-touch, position-based, and time-decay - assign credit with fixed rules. They’re easy to set up, easy to explain, and usually easy to defend in a meeting.
In 2026, they rely on first-party data and UTM parameters, which keeps privacy risk low. But there’s a catch. These models can only see clicks and sessions that leave a durable first-party trail. So if a channel shaped the buying decision without a clean UTM path, it may get less credit than it deserves.
Rule-based models are easy to explain, but they undercredit channels that influence conversions without a clean first-party trail.
Data-driven attribution (DDA) takes a different path. It uses machine learning to estimate the weight of touchpoints when direct signal is missing. It works best when at least 70% of the journey is observed deterministically. Drop below that mark, and the model starts filling in too many blanks.
Browser limits make that harder. Safari’s ITP, for example, shortens lookback windows and removes earlier touchpoints from view. So even a smart model can end up working with an incomplete story.
Aggregated Attribution, MMM, And Cohort Measurement
When person-level signal gets too thin to trust, aggregate models become the safer option.
Aggregated attribution measures impact at the campaign, geo, or audience level instead of by individual user. Chrome’s Attribution Reporting API is a good example. It returns aggregate conversion data and adds built-in “noise” to protect privacy.
Marketing Mix Modeling (MMM) goes a step further. It uses past spend and sales data to estimate channel contribution across the full mix, including offline channels that digital attribution can’t measure well. That matters if your team is trying to connect paid media, brand spend, retail activity, and other inputs in one view.
Modern Bayesian MMM tools like Meta’s Robyn and Google’s Meridian have also changed the pace. What used to run on annual or quarterly cycles can now refresh weekly or daily. That doesn’t make MMM a tool for minute-by-minute decisions, but it does make it far more useful for planning than it used to be.
For B2B teams, cohort- or account-level measurement often fits better. Instead of asking, “Which person clicked?” it asks, “Which account engaged?” That shift helps when user-level signals are patchy or missing. In practice, these models often become the default when consented user-level data is too limited to support stable attribution.
When To Use Each Model Type
Use the model that matches the decision horizon, not the one that sounds the most exact.
| Decision Type | Recommended Model | Key Constraint |
|---|---|---|
| Daily bid/creative optimization | Data-driven MTA or platform-reported conversions | Needs strong first-party signal and modeled conversions |
| Weekly budget shifts | MTA + platform overreporting adjustment | Adjust for known over-reporting before acting |
| Quarterly channel planning | MMM | Requires aggregate historical spend and sales data |
| Causal channel validation | Incrementality testing | Test cycles run 4–8 weeks; not suitable for fast decisions |
A daily bidding choice and a quarterly planning call are not the same job, so they shouldn’t rely on the same model. That sounds obvious, but teams mix this up all the time.
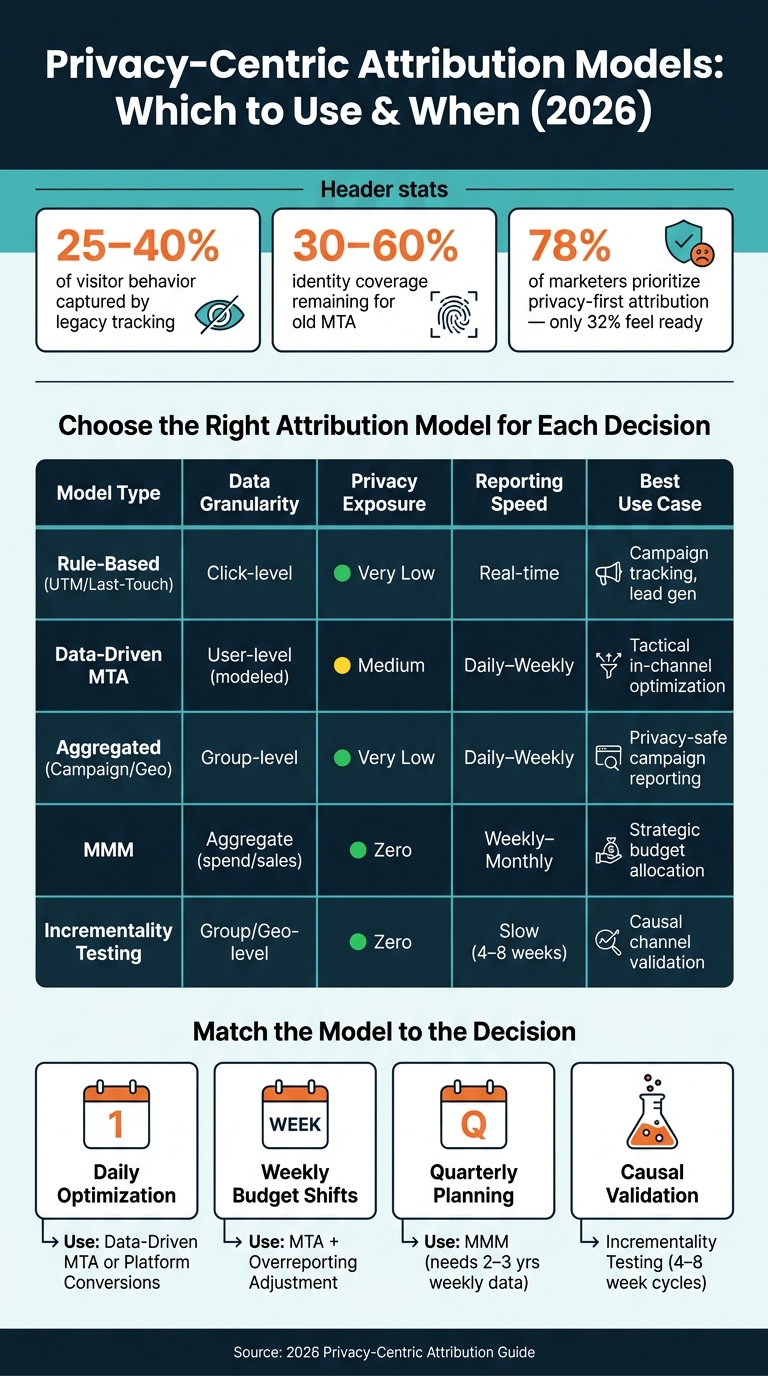
Model Types Compared
Each model family sits at a different point in the trade-off between data detail and privacy exposure. Here’s the practical view.
| Model Type | Data Granularity | Privacy Exposure | Reporting Speed | Best Use Case |
|---|---|---|---|---|
| Rule-based (UTM/last-touch) | Click-level | Very Low | Real-time | Campaign tracking, lead gen |
| Data-driven (MTA) | User-level (modeled) | Medium | Daily to weekly | Tactical in-channel optimization |
| Aggregated (campaign/geo) | Group-level | Very Low | Daily to weekly | Privacy-safe campaign reporting |
| MMM | Aggregate (spend/sales) | Zero | Weekly to monthly | Strategic budget allocation |
| Incrementality testing | Group/geo-level | Zero | Slow (4–8 weeks) | Causal validation |
Each model answers a different kind of question. The next sections show how consent and modeled conversions help improve those answers.
Consent-Led Measurement And Modeled Conversions
Consent Frameworks, First-Party Data, And Server-Side Collection
Consent shapes the size of your measurable dataset. If a user declines, that session does not enter your deterministic dataset. First-party identifiers should only be collected after consent. In practice, that means hashed email, phone, and login ID are the main inputs.
Server-side collection shifts event capture from the browser to your own server. That helps cut data loss from ad blockers and browser restrictions. In many cases, it recovers much more conversion data than client-side pixels. To limit cross-day user linking, rotate salts daily.
This is why reporting now often splits into observed and modeled conversions. Some user activity is measured directly. Some of it has to be estimated.
Observed Versus Modeled Conversions
Observed conversions are directly measured from consented users with usable signal. Modeled conversions estimate activity that could not be observed because consent was denied or the signal was blocked.
That split changes how you read CPA and ROAS. And the effect is not always obvious at first glance. Advertisers using Meta's Conversions API alongside the browser pixel see an average 17.8% lower cost per result. Even so, blended reporting should not be treated as an exact count.
The share that ends up modeled depends on one thing above all: how much consented signal you capture in the first place.
How Consent Rates Affect Attribution Quality
Low consent rates do more than shrink volume. They can also skew the sample toward users who accept tracking, and those users often differ by device, geography, and acquisition source.
That creates a quiet attribution problem. Channels that work better with privacy-conscious users may get undercredited, not because they underperform, but because their conversions are less likely to show up in the observed data.
Before you use modeled outputs to shift budget, you need to know how biased the observed sample is. Then you can calibrate the model with that bias in mind.
Calibrating Attribution With Modeled Data
| Setup | Privacy Level | Estimation Uncertainty | Bidding Impact | Suitable Scenarios |
|---|---|---|---|---|
| Observed Only | High (consented) | High (due to missing data) | Conservative; likely to under-spend | High-intent, bottom-funnel PPC |
| Blended | Medium | Medium | Balanced; ML fills signal gaps | Standard B2B SaaS, multi-touch journeys |
| Modeled Heavy | Very High | Low (at aggregate level) | Strategic; guides long-term budget | Brand campaigns, offline channels |
Calibration is where many teams drop the ball. If blended reporting says a channel drives 18% of conversions, but a geo-lift holdout test shows 7%, you do not brush that off. You adjust the model's confidence range.
A simple way to think about it: modeled results are ranges, not exact totals. Use holdout tests or geo-lift results to calibrate those ranges before tying them to spend decisions.
When user-level signal stays thin, the same approach carries over to aggregate reporting and clean rooms.
Aggregate Reporting, Browser APIs, Clean Rooms, And Stack Integration
Aggregate Reporting, Differential Privacy, And Browser Or OS APIs
When modeled conversions still leave blind spots, aggregate systems become the next layer of measurement. If user-level signal is limited, aggregate reporting gives you campaign-level results instead of individual user paths. Differential privacy adds noise so no one can rebuild individual records from the output.
Browser or OS APIs like the W3C Attribution Reporting API manage attribution on the device itself. They send reports to advertisers with built-in delays and added noise, which helps block timing-based re-identification. In practice, device-side APIs are built for aggregated reports, while server-side tools handle day-to-day reporting. For routine optimization, use server-side Conversion APIs and UTMs.
Clean Rooms And Privacy-Centric Attribution Workflows
A data clean room is a secure, neutral setup where two parties - like an advertiser and a publisher - can match and analyze pseudonymized datasets without either side seeing the other's raw records. Only aggregated outputs leave the clean room.
Clean rooms rely on TEEs, MPC, and differential privacy to keep raw data hidden during matching. They also use governance controls, such as query limits and minimum audience thresholds. A common rule is 100+ users before a segment can be exported, which helps reduce re-identification risk.
Teams often use clean rooms for:
- Cross-publisher measurement
- Retail media reporting
- Overlap detection
- Incrementality lift analysis
- Frequency optimization
The IAB Tech Lab's ADMaP (Ads Data Match Protocol) is one framework used in clean rooms for encrypted matching and aggregated conversion reporting.
Clean rooms make the most sense when you need tighter attribution in a world without third-party cookies. It also helps to collect first-party identifiers - like hashed emails and logged-in states - early in the customer journey, because that can improve match rates. That matters when user-level paths start to disappear.
Where Privacy-Centric Attribution Fits In The Marketing Analytics Stack
Privacy-centric attribution works best as part of a connected stack, not as a standalone product. Each layer handles a different part of the measurement job. If consent capture is weak, storage quality suffers. And if storage quality suffers, modeling has less to work with.
| Stack Layer | Typical Tools / Systems | Main Privacy Consideration |
|---|---|---|
| Consent & Data Capture | Consent Management Platforms, Server-Side Tags, Conversion APIs (Meta CAPI, Google Enhanced Conversions) | Signal synchronization, data minimization |
| Storage | Data Warehouse, CDP, ID Graph | Hashing, encryption at rest, daily salt rotation |
| Modeling | MMM (Meta Robyn, Google Meridian), Clean Rooms, Incrementality Testing | Differential privacy, noise injection, query limits |
| Reporting | BI Tools, Attribution Platforms | Aggregated outputs, minimum cohort thresholds |
Each layer feeds the next. Strong consent capture improves what gets stored. Better storage gives modeling cleaner inputs. Then reporting becomes more useful for budget decisions instead of turning into a guessing game.
The Marketing Analytics Tools Directory can help you map tools to each layer of the stack.
Integration Problems To Solve Early
Some problems show up fast, and they can throw off your reporting if you don't catch them early.
Inconsistent consent signaling is one of the first. Your consent management setup and server-side collection need to stay in sync so the data you collect matches the privacy state you declared.
Duplicate event collection is another common problem. When browser pixels and server-side APIs run at the same time, you need strict deduplication logic to avoid inflated conversion counts.
Identity fragmentation can split the same customer across web and app. Without a consistent hashed identifier, your attribution model may count one customer as two.
Mismatched UTM conventions also create reporting errors. When cookies no longer carry enough context, UTMs become one of the main ways campaign data moves through the funnel. If naming is inconsistent, reports split in messy ways that are hard to clean up.
Platform data and internal BI systems can drift apart too. When that happens, teams start arguing over which number is "right." Use dashboards that reconcile platform data with BI data.
How To Choose A Privacy-Centric Attribution Approach
Once your stack layers are connected, the next step is picking the attribution approach that fits your setup. The right choice depends on how fast you need to make decisions and what kind of signal you still have access to. This part turns the stack into a simple selection rule.
Questions To Answer Before Picking A Model
Use MMM for quarterly cross-channel budget planning, MTA for daily optimization, and account-level measurement for long B2B sales cycles. Long sales cycles usually lean toward account-level measurement or MMM because person-level paths often decay before the deal closes.
If offline spend is more than 30% of your budget, put MMM first. Also, check your data before you commit. You’ll want about 2–3 years of weekly spend and revenue data, plus roughly 100 weekly data points per channel.
Start with those rules. Then look at what your team can actually support day to day.
Recommended Setups By Team Size And Maturity
Once you know which model fits, team size and budget shape how much of the stack you can run well. More spend usually supports more layers. But the core choice still comes back to decision horizon and signal depth.
| Annual Ad Spend | Stack Layer | Primary Outcome |
|---|---|---|
| <$250K | Server-side tracking + conversion APIs | Signal recovery |
| $250K–$1M | Above + channel holdout tests | Tactical efficiency |
| $1M–$5M | Above + open-source MMM + geo-tests | Strategic budget allocation |
| $5M–$20M | Above + managed MMM + quarterly experiments | Allocation efficiency |
| $20M+ | Above + continuous incrementality + identity resolution + clean rooms | Measurement parity at scale |
If your team is lean and spending under $250K per year, fix the data foundation first. That means server-side tracking and conversion APIs before you start shopping for pricey attribution tools. Server-side setup can recover a much higher share of conversion data than client-side pixels alone. In practice, that recovered signal is often worth more than any fancy model built on weak inputs.
For mid-market teams spending $1M–$5M, open-source MMM tools can be a good next layer because the software itself costs $0, even if it still takes analyst or data engineering time. Adding one or two geo-experiments each year gives you a causal check without the drag of a managed platform.
Once a brand gets past $5M in annual ad spend, managed MMM, identity resolution, and clean-room workflows can start to make sense.
Common Mistakes In Privacy-Centric Attribution
Once you’ve picked a model, the next set of problems usually comes from how teams use it. Three mistakes throw attribution off the fastest: treating modeled output like exact truth, using one model for every decision, and skipping governance.
Treating Modeled Results As Exact Counts
Modeled conversions are estimates, not hard counts. That sounds simple, but plenty of platform dashboards mix observed and modeled conversions in ways that make the split easy to miss.
That’s why it helps to compare platform-reported conversions against CRM data or order data. If platform totals come in 40% or more above backend sales, use that gap as a baseline adjustment ratio. If you don’t, the numbers can look better than they are, and that can push budget decisions in the wrong direction. This problem gets even worse when teams try to use the same model for every decision.
Using One Model For Every Use Case
One model can’t answer every question. Daily optimization, quarterly budget allocation, and validation each call for different methods.
When MMM and MTA point in different directions, bring in geo-lift or holdout tests to check which read is closer to what’s happening. Think of it like using different tools in a toolbox - you wouldn’t use a kitchen scale to measure driving distance. Attribution works the same way. And even a good model can fall apart if retention and consent controls are weak.
Ignoring Governance And Data Retention Rules
Governance problems can skew attribution long before they turn into compliance issues. Loose controls around consent, retention windows, and identifier handling can bend the data and also create legal risk under CCPA, VCDPA, CTDPA, and other state-level laws.
Rotate salts daily on hashed identifiers so they don’t turn into cross-day tracking IDs. Set retention windows, access controls, and consent audits before you ship the pipeline.
Conclusion
Privacy-centric attribution in 2026 works like a layered system. First-party identity, server-side collection, aggregate reporting, modeled conversions, and clean rooms all play a part.
That setup matters because missing signals change how much confidence you can have in performance data. Legacy browser-side tracking now captures only 25% to 40% of actual visitor behavior. When that much data drops out, observed-only reporting is too incomplete to guide budget decisions.
Key Takeaways For U.S. Marketing Teams
For U.S. marketing teams, the rule is pretty simple: match the model to the decision.
Use MMM for budget planning at the big-picture level. Use MTA for day-to-day creative and audience tuning. Use incrementality testing to check which channels are actually driving revenue. On the data side, build your first-party identity base with hashed emails and logged-in states. Then make server-side tracking your first infrastructure investment. After that, compare platform-reported conversions against back-end revenue and apply adjustment factors where needed.
Teams that bring together MMM, MTA, incrementality testing, and consented first-party data will make better budget decisions in 2026.
FAQs
How accurate is privacy-centric attribution?
Privacy-centric attribution isn’t a downgrade. It’s a more durable and reliable way to measure marketing, even if it gives up the false precision that came with old cookie-based tracking.
That tradeoff matters. Legacy models often captured only 25% to 40% of visitor behavior. By contrast, privacy-first methods like server-side tracking can recover about 99% of conversion data. That gives businesses a more accurate, consent-compliant view of campaign performance.
Put simply, the old system often looked precise on paper while missing a big chunk of what was actually happening. Privacy-first attribution flips that. It puts aggregate-level reliability first, so teams can make decisions based on a cleaner picture of results.
When should I use MMM instead of MTA?
Use MMM for high-level decisions like cross-channel budget allocation, marginal returns, and total revenue impact. It also works better for measuring offline and upper-funnel channels that pixel-based tracking can miss.
Use MTA for day-to-day optimization inside digital channels, like testing creative variants or audience segments when you have steady first-party data. For the best results, use MMM for strategy and MTA for tactical execution.
Do I need a clean room to get started?
No. You do not need a clean room to get started with privacy-centric attribution.
Clean rooms help with multi-party collaboration and secure dataset matching. But you can build a strong base first with server-side tracking, consistent UTM parameters, marketing mix modeling, and first-party data collection.