Minimizing downtime or eliminating it entirely - what's your priority? That’s the core question when choosing between high availability (HA) and fault tolerance (FT). Both aim to keep systems running during failures, but their approaches differ significantly:
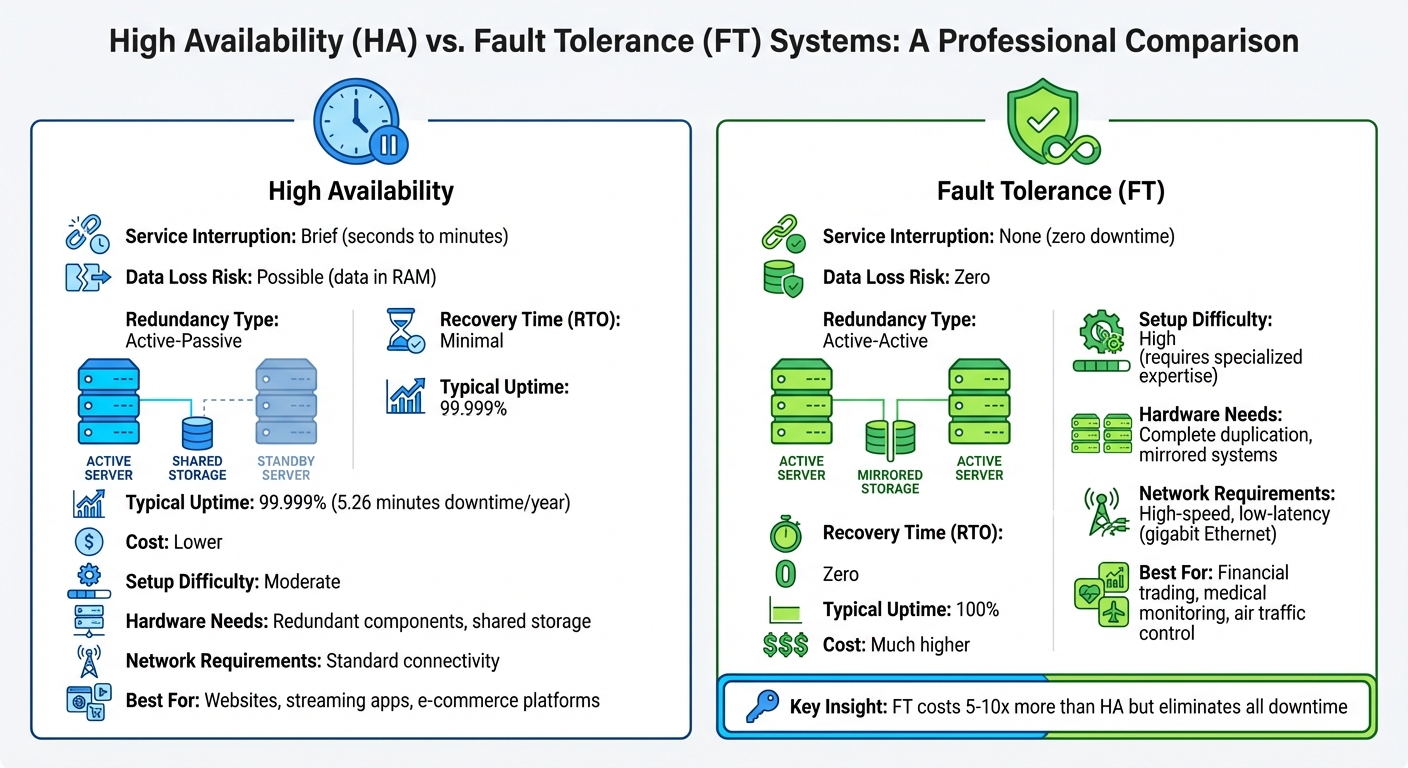
- High Availability: Focuses on reducing downtime with quick recovery (e.g., seconds or minutes). Uses active-passive redundancy, where backups activate only during failures. Affordable but may risk minor data loss.
- Fault Tolerance: Ensures zero downtime and no data loss by running mirrored systems in real-time (active-active redundancy). Perfect for critical systems but comes with steep costs and complexity.
Quick Comparison
| Feature | High Availability | Fault Tolerance |
|---|---|---|
| Service Interruption | Brief (seconds/minutes) | None |
| Data Loss Risk | Possible (in volatile memory) | Zero |
| Redundancy Type | Active-Passive | Active-Active |
| Recovery Time (RTO) | Minimal | Zero |
| Cost | Lower | Much higher |
| Use Cases | Websites, streaming apps | Financial trading, medical systems |
If you can handle brief interruptions, HA is cost-effective. For critical operations, FT is the better choice despite its expense.
High Availability vs Fault Tolerance: Side-by-Side Comparison
High Availability vs. Fault Tolerance | Cloud Academy
sbb-itb-5174ba0
Main Differences Between High Availability and Fault Tolerance
While both approaches aim to safeguard systems from failures, they achieve this in very different ways. Grasping these differences helps you choose the right solution for your specific needs and constraints.
Recovery vs. Continuity
The key difference lies in how each method deals with failures. High availability (HA) accepts short interruptions - usually a few seconds to minutes - while it detects the issue, triggers a failover process, and restores service. Fault tolerance (FT), on the other hand, ensures there’s no interruption at all. As Ronald Caldwell from Liquid Web explains:
The primary difference between high availability and fault tolerance is that fault tolerance offers zero interruption to service for any client.
In practical terms, HA systems need a brief transition period to switch from failed components to backups. FT systems avoid this entirely, as redundant components are already running in parallel, ensuring seamless operation even during a failure.
System Redundancy: Active-Passive vs. Active-Active
Redundancy models vary significantly between HA and FT. High availability typically employs an active-passive setup, where one system actively handles all tasks while a backup remains on standby. If the primary system fails, monitoring software activates the backup. This approach is cost-efficient since the backup system isn’t actively processing tasks until needed.
Fault tolerance, however, uses an active-active configuration. Here, multiple systems operate in perfect synchronization, processing identical data simultaneously. Every transaction, including CPU states and RAM contents, is mirrored in real time. If one system fails, the other takes over instantly without any delay, as it was already handling the workload. The downside? This approach involves higher costs due to full hardware duplication, even during normal operations.
These differences in redundancy directly affect downtime and the risk of data loss.
Impact on Downtime and Data Loss
The operational consequences of these redundancy models are clear: High availability minimizes downtime - usually seconds to minutes - and carries a small risk of data loss. Specifically, any unsaved data in volatile memory (RAM) could be lost during the brief recovery window. This is why HA systems aim for 99.999% uptime rather than absolute continuity.
Fault tolerance, by contrast, ensures zero RTO (Recovery Time Objective) and zero RPO (Recovery Point Objective). There’s no downtime because the service never stops, and no data loss since every transaction is processed simultaneously across systems. But this level of reliability comes with a steep price tag. As Oleg Pankevych, Solutions Architect at StarWind, points out:
If your business can tolerate 1-2 minutes of downtime a year, then sure thing, high availability will be the right option. If even a small downtime generates a huge business impact, it is time to seriously consider implementing fault tolerance.
| Feature | High Availability | Fault Tolerance |
|---|---|---|
| Service Interruption | Brief (seconds/minutes) | None |
| Data Loss Risk | Possible (data in RAM) | Zero |
| Redundancy Type | Active-Passive | Active-Active |
| Recovery Time (RTO) | Minimal | Zero |
| Typical Uptime | 99.999% | 100% |
These technical differences lay the groundwork for understanding the practical considerations and trade-offs involved in implementing each approach.
Implementation and Operational Considerations
Understanding the technical demands and daily management tasks of each approach is crucial for aligning them with your team's capabilities and infrastructure.
Setup Complexity
Setting up high availability systems is relatively manageable. They often rely on widely available hardware and vendor-provided solutions, making them accessible for most IT teams. Key tasks include configuring clustering, load balancers, and failover mechanisms - areas supported by thorough documentation and established tools. Monitoring software plays a central role here, detecting failures and redirecting traffic to backup systems.
In contrast, fault tolerance systems are far more intricate to implement. Pete Scott from Percona highlights this complexity:
Fault-tolerant systems are designed with more complex architectures, requiring sophisticated hardware and software components, along with specialized expertise to design, configure, and maintain.
These systems often use consensus algorithms like Raft or Paxos to keep system states synchronized in real time. This coordination demands a high level of technical expertise and meticulous planning to ensure faults don't cascade across the system.
Infrastructure Requirements
The infrastructure needs for these systems vary significantly. High availability relies on redundant components, such as load balancers, replicated clusters, and shared storage solutions like SANs or software-defined storage. Many HA setups can leverage existing infrastructure, keeping costs moderate while allowing for straightforward scaling.
Fault tolerance, however, requires complete redundancy across the entire system. Every component - hardware, software, and network - must be duplicated and operate in parallel. Specialized hardware is often necessary for instant fault detection. Additionally, high-speed, low-latency networks like gigabit Ethernet are essential for mirroring data without impacting performance. This full duplication, combined with the need for specialized software licenses and higher computational demands, makes fault tolerance a significantly more expensive and resource-intensive option.
Monitoring and Maintenance
The ongoing management tasks for these systems also differ. For high availability, the focus is on monitoring cluster health, managing failover processes, and balancing workloads. Tools such as Prometheus, Datadog, or AWS CloudWatch are commonly used to track system performance and trigger automated failovers when issues arise. The brief transition period - when services shift from a failed primary system to a backup - requires close monitoring to minimize disruptions.
Maintenance for fault tolerance revolves around ensuring real-time synchronization of system states, including RAM, CPU, and storage. Self-healing tools like Kubernetes can automatically detect and replace failed components without manual intervention. To maintain data consistency and prevent performance degradation, techniques such as checksums, parity bits, and hashing are used.
| Aspect | High Availability | Fault Tolerance |
|---|---|---|
| Setup Difficulty | Moderate; uses standard hardware | High; requires specialized systems |
| Hardware Needs | Redundant components, shared storage | Complete duplication, mirrored systems |
| Network Requirements | Standard connectivity | High-speed, low-latency (gigabit Ethernet) |
| Monitoring Focus | Cluster health, failover triggers | Real-time state synchronization |
| Maintenance Impact | Brief crossover downtime (seconds/minutes) | Zero service interruption during updates |
Resource consumption is another key difference. High availability systems optimize resource sharing for efficiency, while fault tolerance systems require dedicated, parallel resources that continuously consume CPU, RAM, and storage - even during normal operations. This constant overhead contributes to the higher operational costs of fault tolerance systems.
Choosing the Right Approach for Data Integration
Building on earlier discussions about technical differences and operational factors, this section focuses on aligning your data integration strategy with business priorities. Whether you opt for high availability or fault tolerance depends on your technical needs and budget considerations.
Assessing Downtime Tolerance
Start by determining how much downtime your systems can handle without major disruptions. For context:
- 99.9% availability allows for up to 8.8 hours of downtime annually.
- 99.99% availability reduces this to 52.6 minutes per year.
- 99.999% availability (often called "five nines") limits downtime to just 5.26 minutes annually.
The stakes are high when downtime translates to financial losses. Gartner estimates that unplanned IT outages cost businesses an average of $5,600 per minute. If your operations can tolerate brief interruptions without severe revenue loss, high availability might suffice. However, fault tolerance becomes essential for mission-critical systems like financial trading, medical monitoring, or emergency response, where even a few seconds of downtime could have serious consequences.
Pete Scott from Percona highlights the distinction:
The goal of employing fault tolerance is to maintain system functionality and data integrity at all times, including during failures or faults. The goal of employing a high availability solution is to minimize downtime and provide continuous access to the database.
Once you've assessed your downtime tolerance, the next step is to evaluate your financial and resource constraints.
Budget and Resource Constraints
After defining your acceptable level of downtime, consider the costs associated with each approach. Implementing fault tolerance can be 5 to 10 times more expensive than a high-availability setup. This cost difference arises from the need for specialized hardware, fully redundant infrastructure, premium software licenses, and advanced technical expertise to maintain mirrored systems.
High availability, on the other hand, is far more cost-effective. It focuses on rapid recovery rather than full redundancy, making it a practical choice for organizations with tighter budgets. To decide, weigh the potential revenue loss from brief outages against the hefty investment required for fault-tolerant systems. For many businesses, achieving "five nines" with high availability offers enough reliability at a fraction of the cost.
Use Case Scenarios
With downtime tolerance and budget in mind, align your strategy with your specific use cases:
- High availability works well for website analytics tools for high-traffic sites, streaming services, batch ETL processes, and non-real-time reporting dashboards. These systems can handle a brief recovery period during failovers without significant disruption to operations.
- Fault tolerance is essential for real-time data pipelines where uninterrupted operation is critical. Examples include payment processing systems, stock trading platforms, life-support medical equipment, and emergency alert systems like Amber Alerts. In these cases, even a momentary lapse in data processing could lead to financial losses, safety risks, or compliance issues.
A hybrid approach often provides the best balance. For example, you can use high availability for less critical application layers while reserving fault tolerance for key data components. This strategy ensures resilience where it’s most needed without overspending on unnecessary duplication.
Conclusion
Summary of Main Differences
High availability focuses on minimizing downtime by enabling rapid recovery, achieving an impressive 99.999% uptime - equivalent to just 5.26 minutes of downtime annually. In contrast, fault tolerance eliminates downtime altogether, ensuring continuous operation even when components fail.
The two approaches differ significantly in recovery methods. High availability depends on a failover process, where a backup system takes over after detecting a failure. This process creates a brief transition period, lasting anywhere from a few seconds to minutes. Fault tolerance, on the other hand, uses mirrored systems running simultaneously, allowing for seamless transitions with no interruptions. This also impacts data integrity: while high availability carries a slight risk of data loss during the failover window, fault tolerance guarantees complete data preservation.
Complexity and cost also vary. High availability setups are moderately complex, relying on familiar tools like load balancers and clustering, which most IT teams can handle. Fault tolerance, however, demands specialized hardware, full redundancy of all components, and advanced technical expertise to maintain real-time synchronization. As a result, fault tolerance is far more expensive to implement than high availability.
These distinctions are critical when deciding how to design your system.
Final Recommendations
High availability is a solid choice if brief outages are acceptable. It’s well-suited for e-commerce platforms, streaming services, and typical web applications where a few minutes of annual downtime won’t result in life-threatening consequences or massive revenue losses. Considering that unplanned database downtime can cost between $300,000 and $500,000 per hour, high availability provides strong reliability at a reasonable cost.
Fault tolerance, however, is essential for mission-critical systems where even a single second of downtime could be catastrophic. Examples include financial trading platforms, medical monitoring devices, air traffic control systems, and emergency alert networks. For many organizations, a hybrid approach is the most practical solution - using fault tolerance for the most critical components and high availability for the broader system. This strategy ensures maximum resilience where it’s needed most without overspending on duplicating less critical systems.
FAQs
How do I choose the right RTO and RPO for my system?
To determine the appropriate RTO (Recovery Time Objective) and RPO (Recovery Point Objective) for your organization, start by evaluating how much downtime and data loss your business can handle.
- RTO refers to the maximum time allowed for systems to be restored after a failure.
- RPO indicates the longest period of data that can be lost due to an incident, measured in time.
For systems that are critical to your operations, opt for lower RTO and RPO values to ensure minimal disruption. On the other hand, if your business can tolerate some downtime or data loss without significant impact, you can set higher values to align with those needs.
Can I combine high availability and fault tolerance in one architecture?
High availability and fault tolerance can absolutely work together to build a system that's incredibly resilient. High availability focuses on reducing downtime by incorporating redundancy, failover processes, and quick recovery strategies. On the other hand, fault tolerance ensures the system keeps running even during failures by relying on complete hardware redundancy.
When combined, these approaches create a system that not only recovers swiftly but also remains operational without interruptions, even when hardware or software issues arise. This dual strategy significantly boosts both uptime and reliability.
What’s the biggest hidden cost of fault-tolerant systems?
The hidden price tag of fault-tolerant systems lies in their complexity, which ramps up testing difficulties and leads to higher costs for hardware, system design, and maintenance. These systems are designed to mask low-level failures, but that can make spotting problems early a real challenge. On top of that, they depend heavily on redundant components - like mirrored systems - that significantly increase both the upfront investment and long-term operational expenses.


